Model Overview
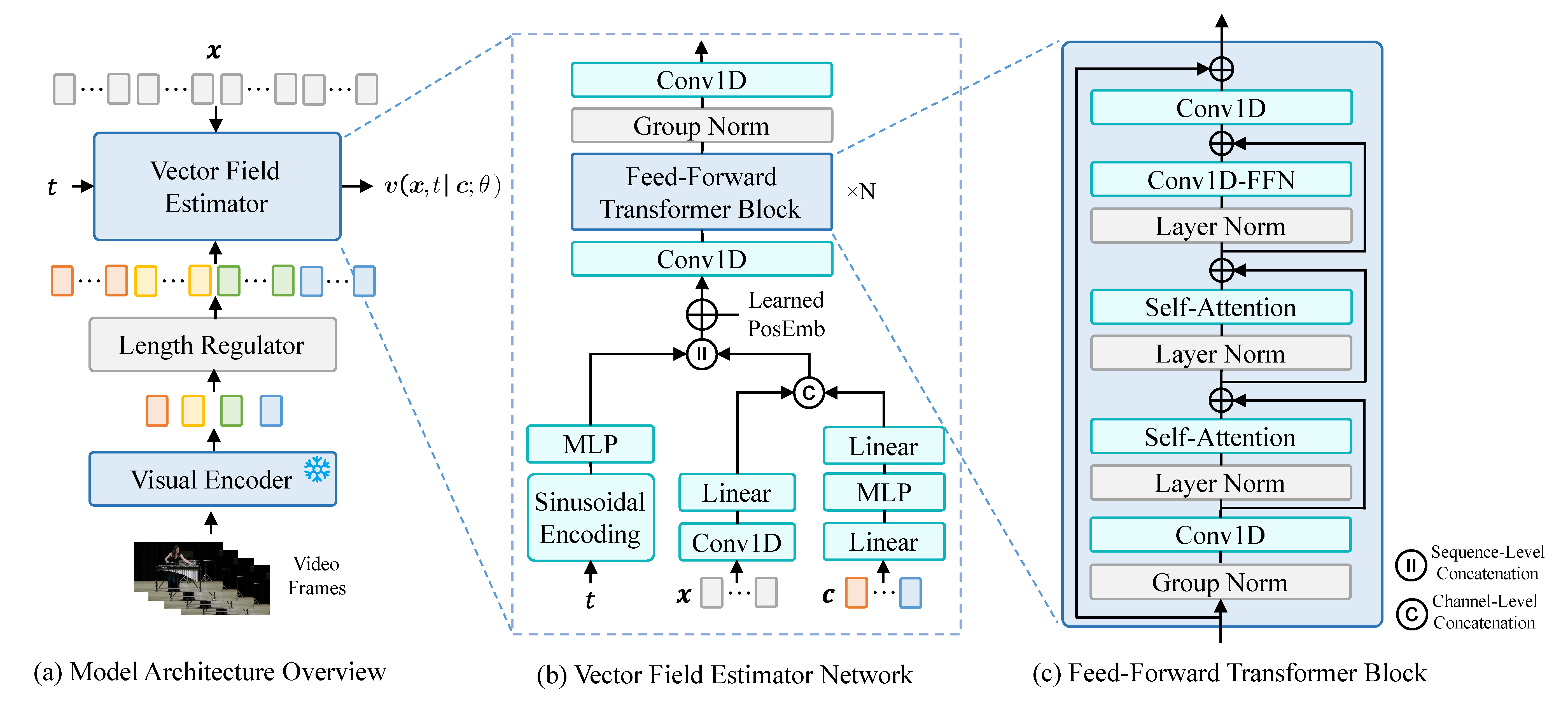
We illustrate the model architecture of Frieren at different levels in the figure. As shown in figure (a), we first utilize a pre-trained visual encoder with frozen parameters to extract a frame-level feature sequence from the video. Usually, the video frame rate is lower than the temporal length per second of the spectrogram latent. To align the visual feature sequence with the mel latent at the temporal dimension for the cross-modal feature fusion mentioned below, we adopt a length regulator, which simply duplicates each item in the feature sequence by the ratio of the latent length per second and the video frame rate for regulation. The regulated feature sequence is then fed to the vector field estimator as the condition, together with x and t, to get the vector field prediction v.
Figure (b) demonstrates the structure of the vector field estimator, which is composed of a feed-forward transformer and some auxiliary layers. The regularized visual feature c and the point x on the transport path are first processed by stacks of shallow layers separately, with output dimensions being both half of the transformer hidden dimension, and are then concatenated along the channel dimension to realize cross-modal feature fusion. This simple mechanism leverages the inherent alignment within the video and audio, achieving enforced alignment without relying on learning-based mechanisms such as attention. As a result, the generated audio and input video sequences exhibit excellent temporal alignment. After appending the time step embedding to the beginning, the sequence is added with a learnable positional embedding and is then fed into the feed-forward transformer. The structure of the transformer block is illustrated in figure (c), the design of which is derived from the spatial transformer in latent diffusion, with the 2D convolution layers replaced by 1D ones. The feed-forward transformer does not involve temporal downsampling, thus preserving the resolution of the temporal dimension and further ensuring the preservation of alignment. The output of the stacked transformer blocks is then passed through a normalization layer and a 1D convolution layer to finally obtain the prediction of the vector field.